
Databases vary in structure, but a key distinction is how they store data: row vs. column-based storage. Selecting the right database type can greatly impact performance, scalability, and efficiency. Let’s explore these two database models in an easy-to-understand way with performance comparisons and an in-depth look at how data is physically stored on disk.
How Data is Stored on Disk: Row vs. Column
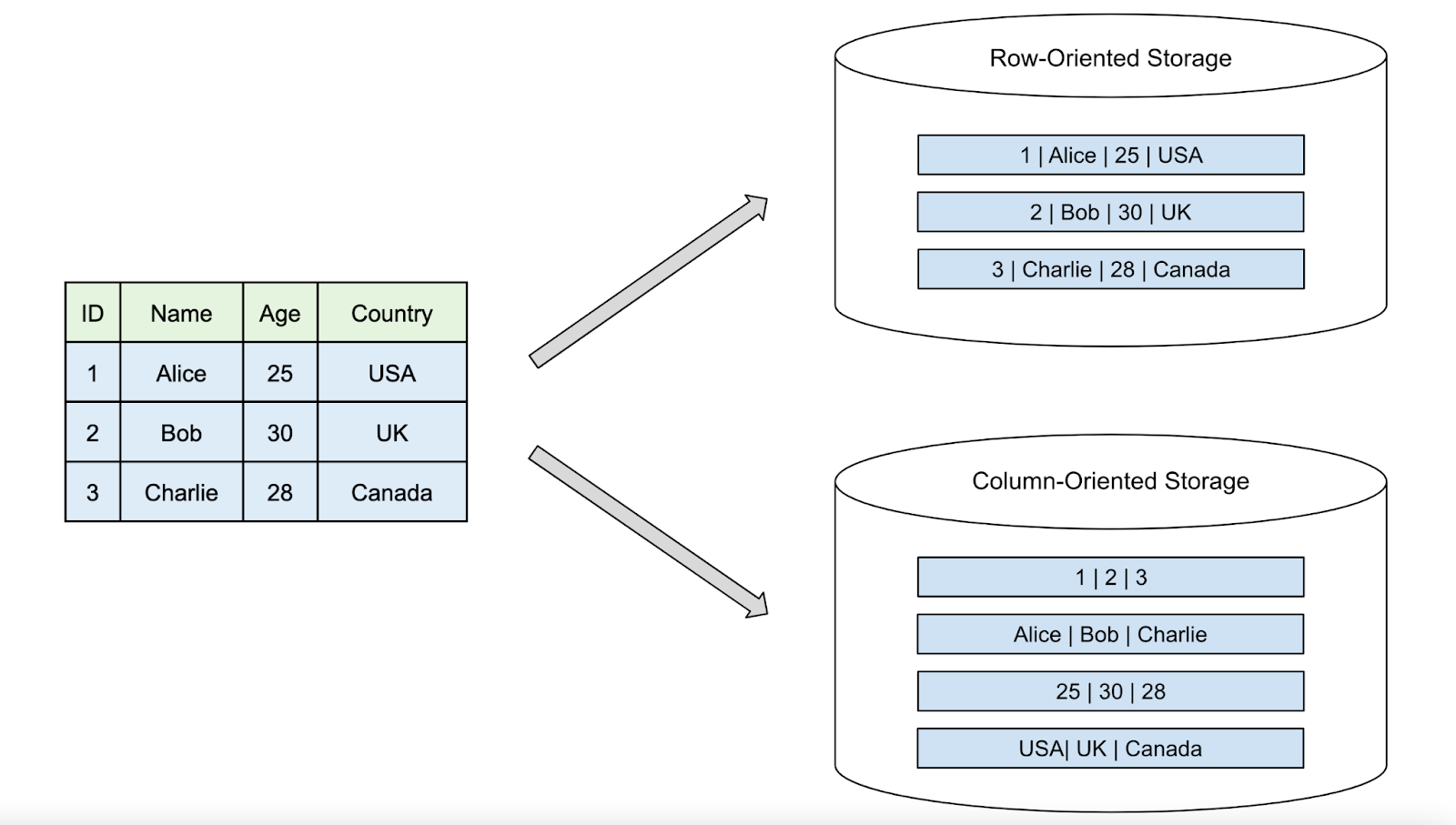
Row-Based Database Storage
A row-based database stores complete records together, meaning all fields for a single row are stored sequentially. This layout is efficient for transactional operations where entire records are frequently read or modified.
Example:
Row 1: [1, Alice, 25, USA]
Row 2: [2, Bob, 30, UK]
Row 3: [3, Charlie, 28, Canada]
Since data is stored row-wise, fetching a full record is efficient, but column-specific queries require scanning unnecessary fields.
Column-Based Database Storage
A column-based database stores data by columns instead of rows, making it ideal for analytical workloads where only specific attributes are accessed frequently.
Example:
Column: ID -> [1, 2, 3]
Column: Name -> [Alice, Bob, Charlie]
Column: Age -> [25, 30, 28]
Column: Country -> [USA, UK, Canada]
This format optimizes columnar queries by allowing selective retrieval of relevant attributes, reducing disk I/O.
Read and Write Operations: Row vs. Column
Row-Based Databases
- Write Operations: Writing an entire row is efficient since all fields are stored together.
- Read Operations: Efficient for retrieving entire records but slower for analytical queries since the database must scan entire rows, even if only specific columns are needed.
Column-Based Databases
- Write Operations: Writing a new row means updating multiple column segments, which is slower than row-based storage.
- Read Operations: Queries retrieving only specific columns are faster because only necessary data is read.
Performance in Transactional & Analytical Workloads
Why Row-Based Databases Excel in Transactional Workloads
Transactional systems involve frequent inserts, updates, and lookups of individual records. Since all attributes of a record are stored together, accessing and modifying a single row requires minimal disk seeks, making operations highly efficient.
- Example: Banking systems frequently update account balances, requiring quick access to individual records.
- Advantage: Since all related data for a transaction is stored together, minimal disk seeks are needed, reducing latency.
- Disadvantage in Analytics: Aggregation queries require scanning entire tables, leading to slower performance when analyzing large datasets.
Why Column-Based Databases Excel in Analytical Workloads
Analytical queries involve aggregations and summarizations over large datasets, where reading entire rows would be inefficient. Since only relevant columns are retrieved, column-based storage significantly speeds up analytical queries.
- Example: A business intelligence system calculating the total revenue per region over a year.
- Advantage: Queries run significantly faster without unnecessary data retrieval.
- Disadvantage in Transactions: Writing individual records requires modifying multiple column stores, making insert/update operations slower compared to row-based databases.
Technical Comparison: Row vs. Column Databases
| Feature | Row-Based Storage | Column-Based Storage |
| Read Performance | Slower for column-specific queries | Faster for analytical queries |
| Write Performance | Faster for frequent updates | Slower for record-level updates |
| Storage Efficiency | Less efficient for analytics | More efficient for large-scale analysis |
| Use Case | OLTP (Transactional) | OLAP (Analytical) |
| Example | Banking, CRM | Data warehouses, analytics |
Query Performance Comparison: Row vs. Column
Scenario 1: Calculating the Average Age of Customers by Country
- Row Database Query Execution
SELECT country, AVG(age) FROM customers GROUP BY country;
⏳ Time taken: ~500ms (Reads all rows, even if only two columns are needed) - Column Database Query Execution
SELECT country, AVG(age) FROM customers GROUP BY country;
⚡ Time taken: ~120ms (Reads only country and age columns, optimizing query speed)
Scenario 2: Fetching a Single Customer Record by ID
- Row Database Query Execution
SELECT * FROM customers WHERE ID = 3;
⚡ Time taken: ~50ms (Efficient, as the entire row is stored together and retrieved quickly) - Column Database Query Execution
SELECT * FROM customers WHERE ID = 3;
⏳ Time taken: ~200ms (Slower, as data is stored column-wise and requires multiple lookups to reconstruct the record)
Row vs. Column – Which Database Should You Choose?
- Use a row-based database for transactional applications that require frequent inserts, updates, and full-record retrievals (e.g., banking, e-commerce).
- Use a column-based database for analytical applications requiring fast data aggregation and reporting (e.g., business intelligence, data warehousing).
- Hybrid Approaches: Many organizations use both types to balance transaction efficiency and analytical performance.
Choosing the right database ensures better performance, scalability, and efficiency for your application.


