
Apache Spark has revolutionized the world of big data analytics, offering unprecedented speed, scalability, and ease of use for processing massive datasets. This comprehensive Apache Spark guide will take you from beginner to advanced practitioner, covering everything you need to know about how to do big data analytics with Apache Spark. Whether you’re a data engineer, data scientist, or developer looking to harness the power of distributed computing, this tutorial provides practical examples, real-world use cases, and hands-on code to accelerate your journey.
With Apache Spark processing data up to 100x faster than Hadoop MapReduce for in-memory operations, it’s become the de facto standard for big data processing across industries. From Netflix using Spark for real-time recommendations to Uber leveraging it for dynamic pricing algorithms, organizations worldwide are transforming their data infrastructure with this powerful engine
What is Apache Spark?
Apache Spark is a unified analytics engine designed for large-scale data processing and big data analytics. Originally developed at UC Berkeley in 2009, Spark has evolved into one of the most popular big data frameworks, supporting multiple programming languages including Python (PySpark), Scala, Java, and R
Unlike traditional big data tools that rely heavily on disk storage, Apache Spark’s revolutionary in-memory computing capability enables it to cache intermediate data in RAM, dramatically reducing processing time. This architectural advantage makes Spark particularly effective for:
- Iterative machine learning algorithms
- Interactive data analysis
- Real-time stream processing
- Complex ETL operations
Key Features of Apache Spark
- 🚀 Lightning-Fast Processing: In-memory data processing delivers speeds up to 100x faster than disk-based systems
- 🔧 Multi-Language Support: Native support for Scala, Python, Java, and R with identical APIs
- 📊 Unified Platform: Single framework for batch processing, streaming, SQL queries, machine learning, and graph processing
- ⚡ Fault Tolerance: Automatic recovery through RDD lineage tracking without expensive replication
- 📈 Dynamic Scalability: Seamlessly scales from single machines to thousands of nodes
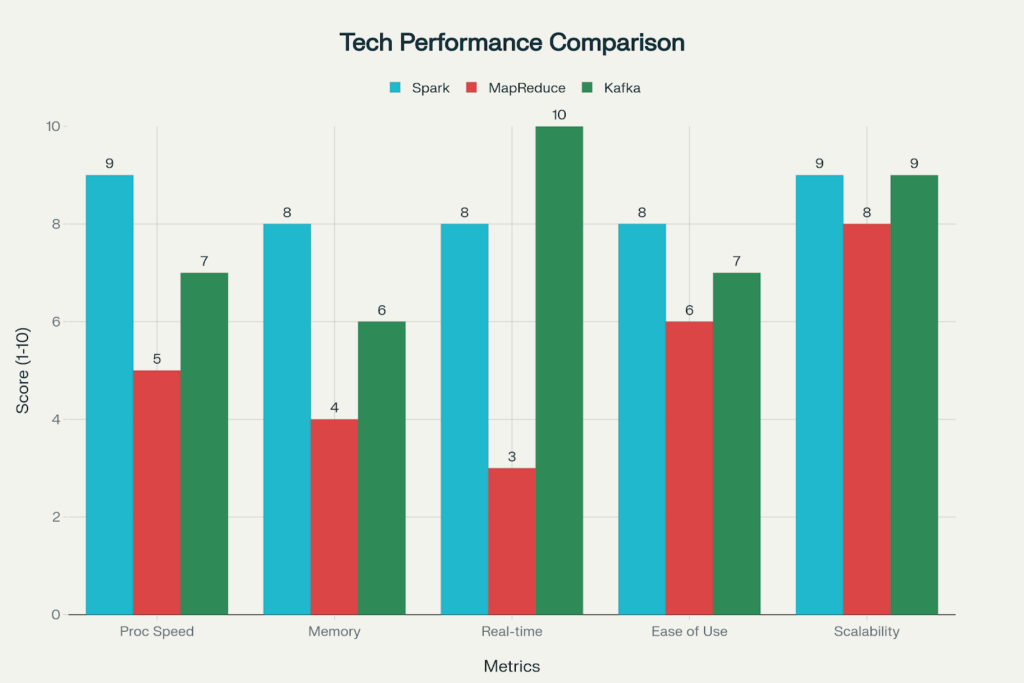
Comparison of Apache Spark vs Hadoop MapReduce vs Apache Kafka across key performance metrics
Apache Spark Architecture: How It Works Internally
Understanding how Apache Spark works internally is crucial for optimizing performance and building efficient big data applications. Spark follows a master-slave architecture with several key components:
Core Components
- Driver Program: The central coordinator that contains your application logic and manages the overall execution. It creates the SparkContext and converts your code into a Directed Acyclic Graph (DAG) for optimized execution.
- Cluster Manager: Manages resource allocation across the cluster. Spark supports multiple cluster managers including YARN, Mesos, Kubernetes, and standalone mode.
- Executors: Distributed agents running on worker nodes that execute tasks and store data. Each application gets its own set of executor processes that run for the application’s lifetime.
- SparkContext: The main entry point that establishes connection to the Spark execution environment. In modern versions, this is typically accessed through SparkSession.
How Spark Processes Data
When you submit a Spark application, here’s what happens internally:
- Job Submission: Driver analyzes your code and creates a logical execution plan
- DAG Creation: Transformations are organized into stages based on data shuffling requirements
- Task Distribution: Cluster manager allocates executors and distributes tasks
- Parallel Execution: Executors process data partitions in parallel across the cluster
- Result Collection: Results are gathered and returned to the driver program
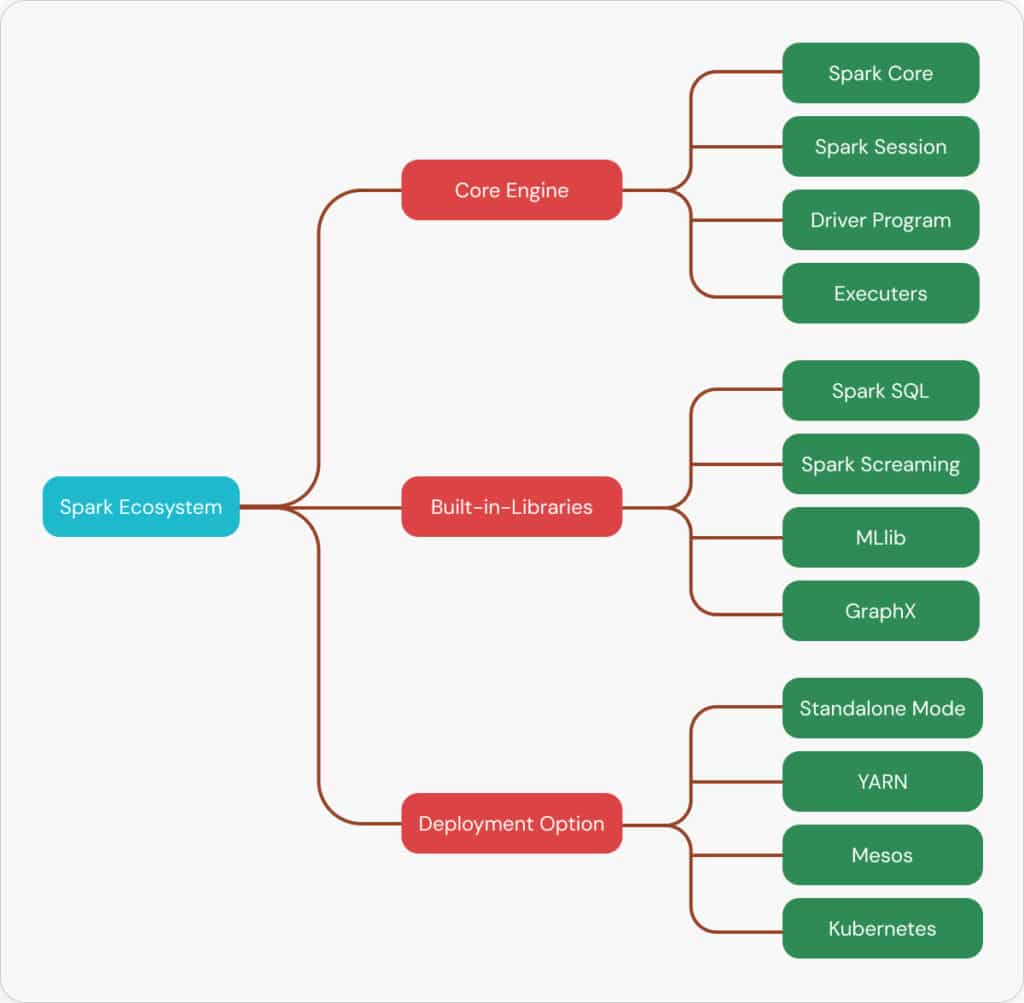
Apache Spark ecosystem and architecture overview showing core components and deployment options
Setting Up Apache Spark: Installation Tutorial
Getting started with Apache Spark installation is straightforward. Here’s a comprehensive guide for different environments:
Prerequisites
Before installing Apache Spark, ensure you have:
- Java 8, 11, or 17 (check with java -version)
- Python 3.8+ for PySpark development
- Sufficient RAM (minimum 16GB recommended for development)
Quick Installation Methods
Method 1: Using PyPI (Easiest)
pip install pysparkMethod 2: Manual Installation
Method 3: Using Docker
docker pull apache/spark:3.5.1
docker run -it apache/spark:3.5.1 /opt/spark/bin/pysparkVerification
Test your installation:
You should see the Spark logo and version information, confirming successful installation.
Apache Spark vs Hadoop MapReduce: Why Spark Wins
The Apache Spark vs Hadoop MapReduce comparison reveals why Spark has become the preferred choice for modern big data processing:
Performance Differences
Speed: Spark processes data up to 100x faster than MapReduce for in-memory operations due to its ability to cache intermediate results in RAM. MapReduce writes intermediate data to disk after each map/reduce operation, creating significant I/O overhead.
Processing Model: While MapReduce follows a rigid two-step process (Map → Reduce), Spark uses a flexible DAG execution engine that optimizes the entire workflow.
Memory Usage: Spark’s in-memory computing requires more RAM but delivers superior performance. MapReduce uses less memory but sacrifices speed.
When to Choose Each
Choose Apache Spark when:
- Speed is critical
- Working with iterative algorithms (machine learning)
- Need real-time processing capabilities
- Want unified platform for multiple data processing tasks
- Team prefers high-level APIs
Choose Hadoop MapReduce when:
- Cost is primary concern (lower memory requirements)
- Processing extremely large datasets that don’t fit in memory
- Need proven stability for batch processing
- Working with write-heavy workloads
Big Data Analytics with Apache Spark: Real-World Use Cases
Big data analytics with Apache Spark powers critical applications across industries. Here are proven use cases where Spark excels:
- Real-Time Fraud Detection:
Financial institutions use Spark Streaming to analyze transaction patterns in real-time, identifying suspicious activities within milliseconds. - Recommendation Systems:
Companies like Netflix and Spotify leverage Spark’s MLlib to build collaborative filtering models that process billions of user interactions. - IoT Data Processing:
Manufacturing companies use Spark to process sensor data from thousands of devices, enabling predictive maintenance and quality control. - Customer Segmentation:
Retailers analyze purchasing patterns using Spark’s advanced analytics capabilities to create targeted marketing campaigns. - Log Analysis and Monitoring:
Tech companies process terabytes of log data daily using Spark to identify performance bottlenecks and system issues.
Hands-On Apache Spark Tutorial: Complete Code Examples
Let’s dive into practical Apache Spark tutorial examples that demonstrate big data analytics capabilities:
This comprehensive example demonstrates:
- SparkSession initialization with optimizations
- Advanced data analytics with grouping and aggregations
- Customer segmentation using conditional logic
- Machine learning with linear regression
- Complex SQL queries with window functions
- Performance optimization techniques
Key PySpark Commands for Big Data Processing
Here are essential PySpark commands every data professional should know:
1. Data Loading and Exploration
2. Data Transformation and Filtering
3. Aggregations and Grouping
Apache Spark Machine Learning: MLlib in Action
Apache Spark’s MLlib provides scalable machine learning algorithms optimized for big data. Here’s how to build predictive models:
Linear Regression Example
Classification with Random Forest
Apache Spark Streaming: Real-Time Data Processing
Spark Streaming enables processing of live data streams with the same APIs used for batch processing. Here’s how to build streaming applications:
Basic Streaming Example
Kafka Integration
Performance Optimization: Best Practices
Optimizing Apache Spark performance is crucial for production workloads:
Memory Management
Caching Strategies
Partitioning Optimization
Apache Spark SQL: Querying Big Data
Spark SQL provides a familiar SQL interface for big data processing:
Advanced SQL Queries
DataFrame API Equivalent
Apache Spark vs Kafka vs Databricks: Understanding the Ecosystem
Understanding how Apache Spark compares with Kafka and Databricks helps choose the right tool for specific use cases:
Apache Kafka
Primary Function: High-throughput message broker for real-time data streaming
Best For: Data pipelines, event processing, real-time data ingestion
Latency: Sub-millisecond latency for data delivery
Apache Spark
Primary Function: Unified analytics engine for data processing
Best For: Batch processing, machine learning, complex analytics
Latency: Higher than Kafka but optimized for throughput
Databricks
Primary Function: Managed Spark platform with additional enterprise features
Best For: Collaborative analytics, managed infrastructure, MLOps
Integration: Built on Spark with enhanced UI and collaboration tools
Frequently Asked Questions
Conclusion: Mastering Apache Spark for Big Data Success
Apache Spark has fundamentally transformed how organizations approach big data analytics, offering unmatched speed, versatility, and ease of use. Through this comprehensive Apache Spark tutorial, we’ve explored everything from basic installation to advanced machine learning applications, providing you with the knowledge and practical skills needed to excel in today’s data-driven landscape.
The key advantages that make Apache Spark the preferred choice for big data analytics include its lightning-fast in-memory processing, unified platform supporting multiple data processing paradigms, and extensive ecosystem of libraries and tools. Whether you’re building real-time recommendation systems, processing IoT sensor data, or developing machine learning models at scale, Spark provides the performance and flexibility needed for success.
As you continue your Apache Spark journey, remember that mastery comes through practice and real-world application. Start with simple examples, gradually work up to complex analytics projects, and always focus on understanding the underlying concepts rather than just memorizing syntax. The big data landscape continues evolving rapidly, and Apache Spark remains at the forefront of this transformation, making it an essential skill for data professionals in 2025 and beyond.
By implementing the techniques, code examples, and best practices covered in this guide, you’ll be well-equipped to tackle any big data challenge and drive meaningful insights from your organization’s data assets. The future of data processing is distributed, intelligent, and lightning-fast—and with Apache Spark, that future is already here.


