The modern enterprise faces an unprecedented challenge: managing explosive data growth while extracting meaningful insights that drive business value. For decades, organizations have struggled with a fundamental trade-off between data warehouses and data lakes, sacrificing either flexibility for performance or cost-effectiveness for governance. Enter the data lakehouse, a revolutionary architecture that eliminates this compromise entirely.
The Problem with Traditional Data Architectures
Traditional data management has forced businesses into an either-or decision between two imperfect solutions.
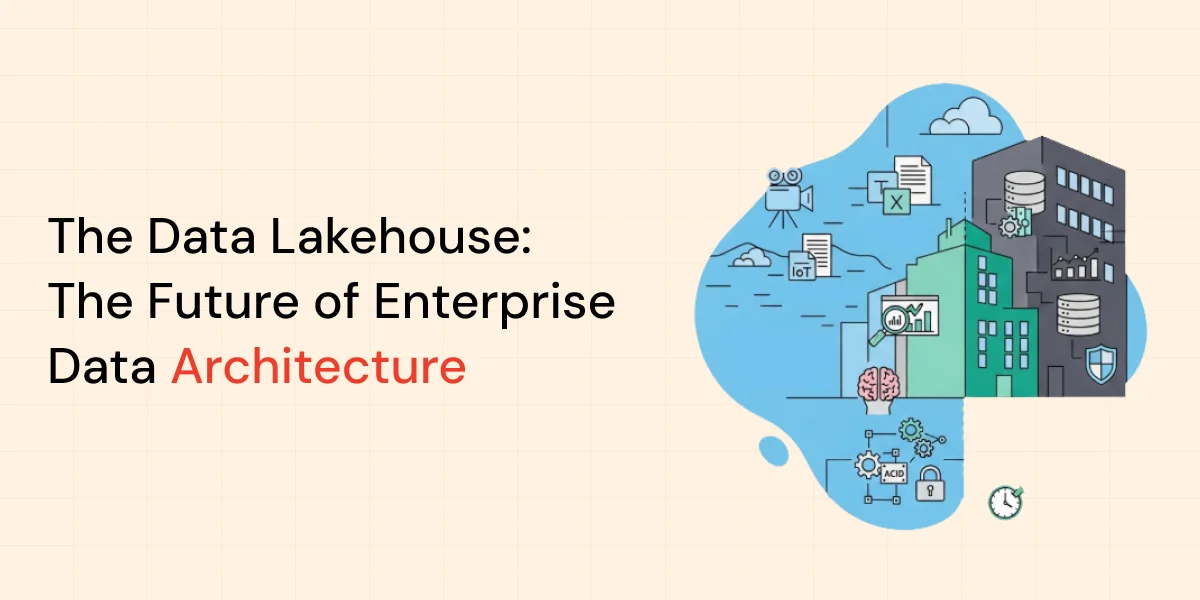
Data warehouses excel at structured analytics and business intelligence but struggle with modern data realities. They require expensive, rigid schemas that must be defined upfront, making them poorly suited for the diverse, rapidly changing data types generated by IoT devices, social media, and modern applications. Their proprietary nature and coupled compute-storage models often result in prohibitive costs as data volumes scale.
Data lakes address the cost and flexibility limitations of warehouses by storing vast amounts of raw data in any format at scale. However, their “schema-on-read” approach can quickly devolve into “data swamps” without proper governance. Most critically, traditional data lakes lack ACID transaction support, making them unsuitable for mission-critical business intelligence workloads.
This dual-architecture approach creates significant operational challenges: complex ETL pipelines between systems, data duplication, inconsistencies, and delays in making fresh data available for analysis. Organizations end up managing two separate platforms with different tools, governance policies, and teams—increasing complexity and costs while reducing agility.
What is a Data Lakehouse?
A data lakehouse is a modern data architecture that combines the best features of both data lakes and data warehouses into a single, unified platform. It leverages cost-effective cloud object storage while adding robust metadata layers and data management capabilities that provide structured schemas, ACID transactions, and enterprise-grade governance.
Key Architectural Characteristics
Unified Data Support: The lakehouse handles all data types, structured, semi-structured, and unstructured, within a single platform, eliminating the need for specialized systems.
ACID Transactions on Data Lakes: This is perhaps the most critical differentiator. Lakehouses bring database-level reliability directly to data lakes, ensuring consistency even with concurrent operations.
Schema Flexibility with Enforcement: Unlike the rigid “schema-on-write” of warehouses or the chaotic “schema-on-read” of lakes, lakehouses offer dynamic schema management. They support schema enforcement for structured data while maintaining flexibility for raw datasets, with built-in schema evolution capabilities.
Decoupled Compute and Storage: Resources scale independently, allowing organizations to optimize both cost and performance by paying only for needed compute power.
Open Standards: Built on open file formats like Apache Parquet, Delta Lake, Apache Iceberg, and Apache Hudi, lakehouses prevent vendor lock-in and ensure interoperability.
Real-time Processing: Native support for both streaming and batch data processing enables immediate insights from fresh data.
Data Lakehouse vs. Data Lake vs. Data Warehouse: A Clear Comparison
To truly appreciate the transformative potential of a data lakehouse, it is essential to understand how it addresses the inherent trade-offs and limitations of its predecessors. The following table provides a comparative analysis of data warehouses, data lakes, and data lakehouses across key architectural and functional dimensions.
| Feature | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
| Data Types Supported | Structured (Relational data from transactional systems) | All data (Structured, Semi-structured, Unstructured in native format) | All data (Structured, Semi-structured, Unstructured in native format) |
| Schema Approach | Schema-on-write (designed prior to implementation, ETL) | Schema-on-read (defined at analysis, ELT) | Flexible (Schema enforcement for structured, schema-on-read for raw, schema evolution) |
| ACID Transactions | Yes | No | Yes |
| Performance | Fastest query performance (local storage) | Prioritizes storage volume/cost (reasonable speeds) | High performance (optimized query engines, decoupled compute/storage, indexing) |
| Cost | Higher (proprietary systems, coupled storage/compute) | Lower (cloud object storage) | Low (leveraging cloud object storage, reduced ETL/duplication, single platform) |
| Primary Use Cases | Batch reporting, BI, visualizations | ML, AI, data science, exploratory analytics, big data | BI, ML, AI, real-time analytics, data science, operational analytics |
| Data Quality & Governance | Highly curated, central version of truth | May contain raw, uncurated data; prone to data swamps without governance | Improved through schema enforcement, metadata management, unified governance |
| ETL/ELT Approach | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) | Supports both ETL or ELT |
| Real-time Streaming Support | Mostly batch processing | Can handle real-time ingestion | Full support for real-time and batch processing |
The comparative table clearly illustrates how the data lakehouse effectively bridges the gap between the data lake and the data warehouse, addressing their respective limitations. The lakehouse brings ACID transaction capabilities directly to data lakes while maintaining cost-effective storage, offers flexible schema management that adapts to changing business needs, and supports diverse workloads from traditional BI to advanced AI initiatives on a single platform.
The Medallion Architecture: Organizing Data for Success
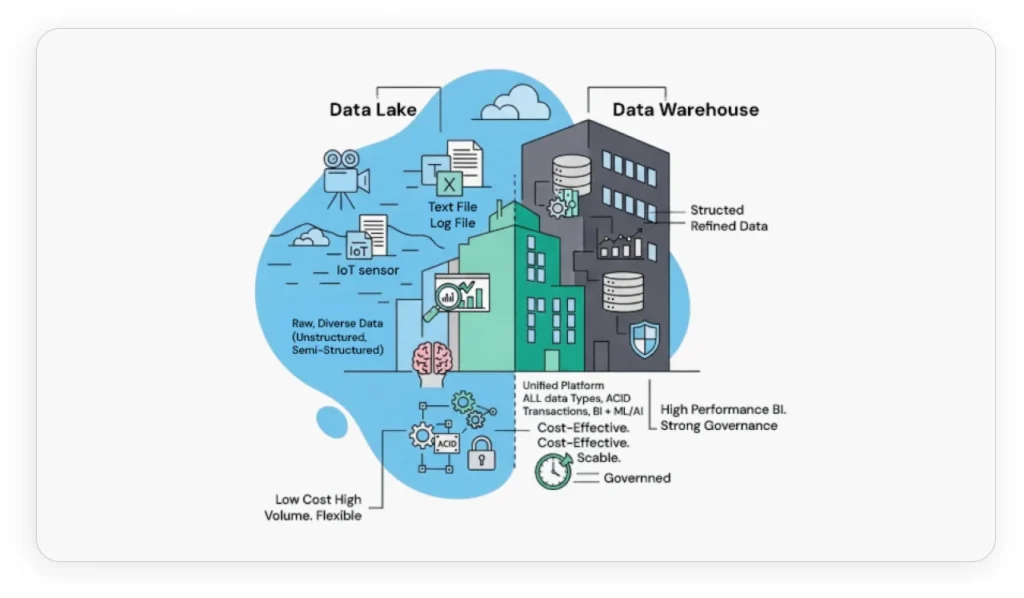
Most successful lakehouse implementations follow the Medallion architecture pattern, which organizes data into three progressive quality layers:
- Bronze Layer (Raw Zone): Ingests source data in its original format with minimal processing, serving as an immutable source of truth. Data is typically append-only, preserving raw integrity for auditing, compliance, and potential reprocessing.
- Silver Layer (Cleansed Zone): Cleanses, standardizes, and enriches Bronze data, creating high-quality, enterprise-ready datasets. This layer implements automated data quality checks and handles schema evolution gracefully using open table formats like Delta Lake, Apache Iceberg, or Apache Hudi.
- Gold Layer (Curated Zone): Contains aggregated, business-ready data optimized for specific analytics use cases, BI dashboards, and machine learning models. Tables often conform to denormalized designs for optimal query performance.
This layered approach ensures data quality improves systematically while maintaining traceability and enabling different teams to access data at the appropriate level of refinement.
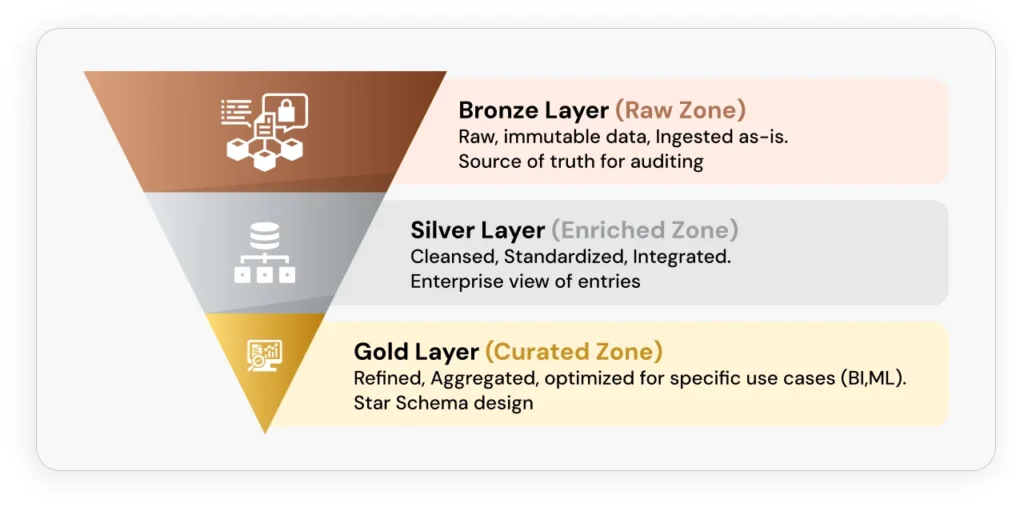
Why Every Business Needs a Lakehouse
Simplified Architecture and Reduced Complexity
By eliminating the need for separate data lake and warehouse systems, lakehouses dramatically simplify data architecture. This consolidation removes complex ETL processes, reduces data quality issues, and accelerates time-to-insight by allowing analytical tools to connect directly to source data.
Significant Cost Optimization
Lakehouses deliver substantial economic benefits through several mechanisms:
- Leveraging low-cost cloud object storage instead of expensive proprietary systems
- Eliminating duplicate infrastructure and licensing costs
- Reducing ETL development and maintenance expenses
- Optimizing compute costs through on-demand, decoupled resources
The financial impact is particularly pronounced for organizations with large data volumes that previously maintained parallel infrastructures.
Enhanced Data Quality and Governance
The unified environment makes it significantly easier to implement consistent governance and security controls across all data types. Schema enforcement maintains data integrity while reducing duplication establishes a reliable single source of truth. This unified approach simplifies policy management and ensures consistent application of privacy, security, and compliance rules.
Superior Performance and Limitless Scalability
Designed for big data demands, lakehouses offer virtually unlimited scalability through independent scaling of compute and storage resources. By minimizing data movement between systems, they ensure faster data availability and fresher insights. ACID transaction support guarantees consistency even with concurrent access, critical for high-performance analytical workloads.
Unlocking Advanced Analytics and AI
Perhaps the most transformative advantage is the lakehouse’s ability to support advanced analytics, AI, and machine learning across all data types within a unified platform. This capability enables organizations to move beyond historical reporting to real-time predictive insights. Data transforms from a historical record into a strategic asset that enables immediate, proactive business actions.
Leading Lakehouse Platforms
Databricks Lakehouse Platform
Databricks pioneered the lakehouse concept with its integrated platform built on Delta Lake and Unity Catalog. Delta Lake provides ACID transactions, versioning, and schema evolution for data lakes, while Unity Catalog offers unified governance across all data and AI assets. The platform enables analytics and machine learning workloads side-by-side, eliminating data duplication and context switching.
AWS Lakehouse Architecture
AWS provides a comprehensive service ecosystem for building lakehouses, centered on Amazon S3 storage with services like AWS Glue, Amazon Athena, and Amazon EMR. The architecture commonly follows a three-tier S3 data lake pattern with technologies like Apache Hudi providing ACID capabilities. AWS Lake Formation simplifies setup and governance while services like Amazon Redshift Spectrum enable direct querying of data lake assets.
Microsoft Fabric Lakehouse
Microsoft Fabric offers a unified SaaS platform that merges data lake flexibility with warehouse capabilities through OneLake and Delta Lake integration. OneLake serves as a single data repository built on Azure Data Lake Storage Gen2, while standardizing on Delta Lake ensures seamless access across all compute engines. The platform integrates data engineering, warehousing, real-time analytics, and Power BI into one cohesive environment.
Implementation Best Practices
Start with Clear Goals: Define specific business objectives and use cases before implementation. Assess current data infrastructure to understand existing types, sources, and challenges.
Invest in Metadata Management: Early implementation of a robust data catalog is foundational for schema management, lineage tracking, and data discovery.
Implement Proper Data Organization: Strategic partitioning based on query patterns dramatically improves performance and reduces costs. Aim for larger file sizes (approximately 1 GB) and consider techniques like Z-Ordering for optimization.
Establish Security from Day One: Implement fine-grained access controls using RBAC, column/row-level security, and comprehensive data encryption.
Take a Phased Approach: Migrate incrementally by use case or data domain rather than attempting a “big bang” transformation.
Overcoming Common Challenges
While transformative, lakehouse adoption isn’t without challenges. The technology’s relative newness can create uncertainty, and implementation complexity requires careful planning and research. Success often demands diverse skills including data engineering, analytics, and governance expertise.
Common pitfalls include treating lakehouses as “just another data lake,” poor data modeling practices, and inadequate metadata management. Organizations should approach adoption with comprehensive training programs and potentially leverage integrated vendor platforms that abstract underlying complexity.
The Path Forward
The data lakehouse represents a fundamental evolution in enterprise data management. By seamlessly combining warehouse reliability with data lake flexibility and cost-effectiveness, it provides a truly unified platform for all data workloads. This architecture eliminates historical challenges of data silos and fragmented landscapes while unlocking unprecedented capabilities for advanced analytics and AI.
The future belongs to organizations that can rapidly transform data into actionable insights. The lakehouse architecture doesn’t just make this possible, it makes it practical, scalable, and cost-effective. For any business seeking to stay competitive and maximize the value of its data assets, adopting a data lakehouse architecture has evolved from an option to a strategic imperative.
The question isn’t whether to adopt lakehouse architecture, it’s how quickly you can begin the transformation that will power your next generation of business insights.
Frequently Asked Questions
Bronze: Raw data ingest
Silver: Cleansed and validated
Gold: Curated and business-ready
This layered structure improves quality, traceability, and usability, ensuring teams always work with the right level of refined data.
Databricks (Delta Lake, Unity Catalog)
AWS (S3, Glue, Athena, EMR, Lake Formation)
Microsoft Fabric (OneLake, Delta Lake)
Each offers unique strengths in analytics, integration, and scalability.


